atom.data-analyst.classify-data-sensitivity
データの機密度を見極める
データの機密度を見極める 会社で扱うデータには、「誰が見ても問題ないもの」と「見る人を間違えると大トラブルになるもの」がありますよね。 たとえば、料理のレシピは誰に見せても安心ですが、冷蔵庫に貼ってある「私の健康診...
成果物成果物このレッスンが終わったとき、あなたの手元に残る具体的な成果物です(例: 公開済みの Web ページ、動作するフォームなど)。
証跡証跡成果物が正しく作れたことを確認するためのチェックリストです(例: ブラウザで動作する、フォーム送信で値が保存される)。
メディアメディアレッスン内に出てくる図や動画のスロットです。実際の画面やイメージで理解を補助します。
レッスン本文
データの機密度を見極める
会社で扱うデータには、「誰が見ても問題ないもの」と「見る人を間違えると大トラブルになるもの」がありますよね。 たとえば、料理のレシピは誰に見せても安心ですが、冷蔵庫に貼ってある「私の健康診断の結果」は人には見せたくありません。 この Atom では、あなたが日々ふれるデータを「どのくらい気をつけて扱うべきか」の4段階に分ける力を身につけます。
所要時間: 約15分
ゴール: 手元のデータの各列に機密度レベルを割り当て、分類結果をまとめた文書を1枚作る
機密度のレベルを知る
データの機密度(=データが漏れたときのダメージの大きさ)は、一般的に次の4段階で考えます。
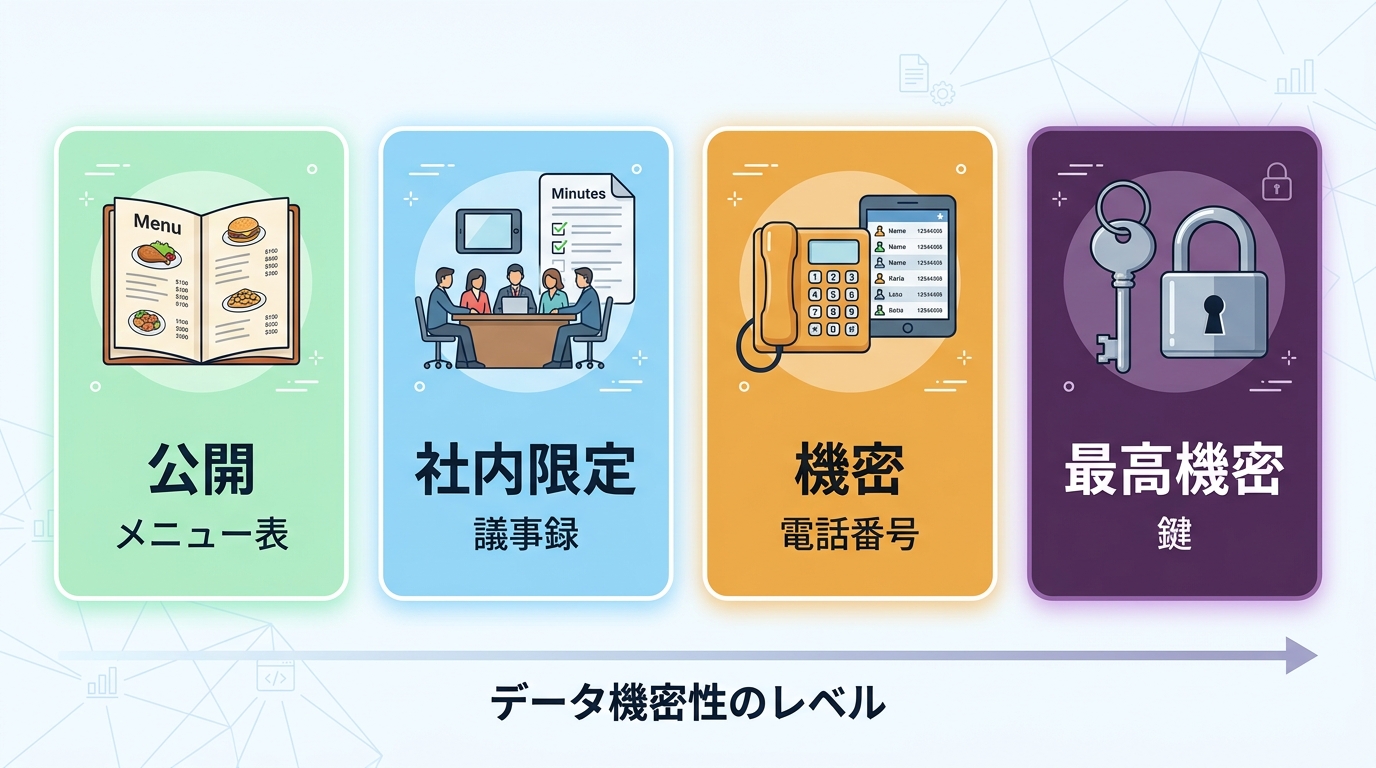
| レベル | 名前 | たとえ | 漏れたらどうなる? |
|---|---|---|---|
| 1 | 公開(=だれでも見てOK) | 店のメニュー表 | 何も問題なし |
| 2 | 社内限定(=会社の人だけ) | 会議の議事録 | 少し気まずい |
| 3 | 機密(=関係者だけ) | 顧客の連絡先 | 取引に影響するかも |
| 4 | 最高機密(=ごく少数だけ) | 給与情報・パスワード | 法的・金銭的トラブル |
まずはこの表を頭の片隅に置いてください。迷ったときはいつでもここに戻ればOKです。
AIに「判断の叩き台」を作ってもらう
いきなり自分だけで分類するのは大変です。まず AI に叩き台(=最初のたたき案)を出してもらい、それを人間が確認・修正する流れが効率的です。
ステップ1:データの列名をリストアップする
あなたの手元にあるスプレッドシートや CSV ファイルの列名(ヘッダー行)を書き出します。
例:名前, メールアドレス, 購入日, 商品名, 合計金額
ステップ2:AIにプロンプトを送る
ChatGPT や Claude に、次のようなプロンプト(=AIへの指示文)をコピペして送ります。
プロンプト例
以下のデータ列について、機密度を4段階(1: 公開、2: 社内限定、3: 機密、4: 最高機密)で分類してください。 各列に対して「レベル」「理由(1行)」「漏れた場合のリスク(1行)」を表形式で回答してください。
列名: 名前, メールアドレス, 購入日, 商品名, 合計金額
AI が返してくる表は、あくまで「叩き台」です。次のステップで人間の目でチェックします。

ステップ3:AIの回答を自分の目で確認・修正する
AI の回答を1行ずつ読み、次の観点でチェックしてください。
- 「これが知らない人に漏れたらどうなる?」 と想像する
- 個人を特定できる情報(名前・電話番号・メールなど)はレベル3以上になっているか?
- 一般公開済みの情報(商品名・定価など)はレベル1になっているか?
- 組み合わせると危険度が上がるデータ(ID+名前など)は単体より高いレベルにしているか?
確認のプロンプト例(修正したい列がある場合)
「メールアドレス」をレベル2(社内限定)としていますが、外部に漏れた場合は迷惑メールや詐欺に使われるリスクがあります。 レベル3(機密)に修正すべきですか? 理由も教えてください。
AI は理由つきで再判定してくれます。最終的な判断はあなた自身が行いましょう。
良い例・悪い例
良い例:
- 「顧客のメールアドレス」→ レベル3(機密)。漏れると迷惑メールや詐欺のリスクがある
- 「商品の定価」→ レベル1(公開)。もともと誰でも見られる情報
悪い例:
- 「顧客のメールアドレス」→ レベル1(公開)と判定。個人情報なのに公開扱いは危険
- 「商品カテゴリー名」→ レベル4(最高機密)と判定。一般情報なのに過剰な制限は業務の邪魔
コツは「漏れたときのダメージ」で考えることです。数字そのもの(センサーの値など)はレベル1ですが、それが「誰の健康データか」がわかる状態だとレベルが上がります。
結果をまとめる
分類が終わったら、結果をまとめた短い文書(Markdown やスプレッドシートでOK)を作ります。
含めるべき項目
- 対象データの名前(例:「2024年 売上データ」)
- 各列の機密度レベルを表にする
- レベル3以上の列には「なぜ機密か」の理由を一言添える
- 全体の代表レベル(=列の中で一番高いレベル)を書く
AIでまとめ文書を作るプロンプト例
以下の分類結果をもとに、「データ機密度分類レポート」をMarkdown形式で作成してください。
- データセット名: 2024年 売上データ
- 分類結果:
- 名前: レベル3(顧客個人を特定できるため)
- メールアドレス: レベル3(漏洩時に詐欺リスク)
- 購入日: レベル2(購買傾向が推測される)
- 商品名: レベル1(公開情報)
- 合計金額: レベル2(取引規模が推測される)
- 全体の代表レベル: レベル3
レポートには「概要」「列ごとの分類表」「レベル3以上の理由」「取り扱い上の注意」を含めてください。
作成したレポートのスクリーンショットが、この Atom の成果物になります。
確認する
以下のチェックリストで最終確認しましょう。すべてにチェックが入ればこの Atom は完了です。
- すべての列に機密度レベル(1〜4)を割り当てた
- レベル3以上の列に「なぜ機密か」の理由が書いてある
- 個人を特定できる情報(名前・電話番号・メールなど)がレベル3以上になっている
- 一般公開済みの情報をレベル1として扱っている
- 列ごとにレベルが違うことを理解している(1つの表の中にレベル1もレベル4もあるのは普通です)
- 分類結果をまとめたレポート文書が1枚できている
- レポートのスクリーンショットを保存した
つまずきポイント
「全部レベル4にしておけば安全では?」
確かに安全ですが、レベル4のデータは扱いがとても厳しくなります。閲覧するだけでも承認が必要だったり、分析に使えなかったりします。適切なレベル分けが一番実務的です。旅行にたとえると、全荷物を金庫に入れると出し入れが大変で旅が楽しめないのと同じです。
「自分の会社だけのルールがあるのでは?」
その通りです。会社によって独自の基準がある場合があります。この Atom は一般的な基準を学ぶものです。会社のルールがある場合は、そちらを優先してください。AIに「当社の情報セキュリティポリシーに照らすとどうか」と聞くときは、ポリシーの要点もプロンプトに貼ると精度が上がります。
「AIに分類させればいいのでは?」
AIは叩き台として非常に便利ですが、機密度の判断には「漏れたらどうなるか」という想像力と、あなたの業務知識が必要です。たとえば「社員番号」が社外に意味を持つかどうかは、会社の事情を知っている人にしか判断できません。AIに叩き台を作ってもらい、人間が最終確認するのがベストな流れです。
「組み合わせで危険になるデータがわからない」
たとえば「年齢」と「住所の一部」は、それぞれ単体ではレベル2程度ですが、組み合わさると個人が特定される可能性があり、レベル3に上がります。迷ったら AI に「この列の組み合わせで個人特定は可能ですか?」と聞いてみましょう。
種類: markdown_doc
検証: basic_manual_check_v1
証跡証跡成果物が正しく作れたことを確認するためのチェックリストです(例: ブラウザで動作する、フォーム送信で値が保存される)。
メディア
必須
なし
あると楽
なし